
Cross validation
Train/Test Split and Cross Validation in scikit-learn
To avoid overfitting, we need to split the available data as a train set and a test set, before we performing a machine learning experiment.
train_test_split
In scikit-learn,there is a simple way to do the split: train_test_split.
let’s take ‘data of iris’ from scikit-learn datasets for example:
iris = datasets.load_iris()
iris.data.shape, iris.target.shape
((150, 4), (150,))
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.4, random_state=0)
X_train.shape, y_train.shape
X_test.shape, y_test.shape
((90, 4), (90,)) ((60, 4), (60,))
As you can see the iris.data have been splited into train(60%) and test sets(40%).
Now we use these two set to fit a model, and get the predictions and the score of this model.
lm = linear_model.LinearRegression()
model = lm.fit(X_train, y_train)
predictions = lm.predict(X_test)
model.score(X_test, y_test)
But train/test split does have its dangers — what if the split we make isn’t random? What if the data is not not evenly distributed? This will result in overfitting, even though we’re trying to avoid it! This is where cross validation comes in.
Cross validation
Cross validation is quit similar to train_test_split, but it’s applied to more subsets. Meaning, we split our data into k subsets, and train on k-1 subsets, and hold one subset for the test. We’re able to hold test set for each of all k subsets.
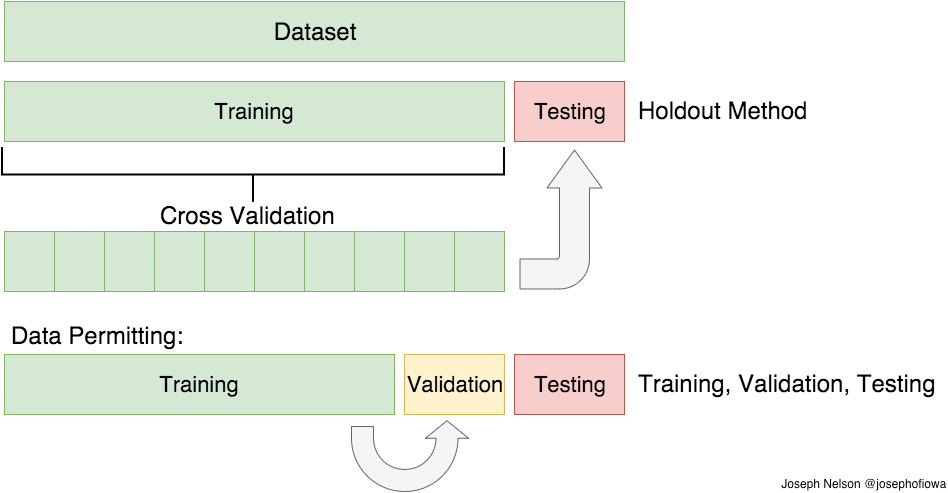
K-Folds Cross Validation
We split our data into k different folds. We use k-1 folds to train our data and leave the last folds as test data. We then average the model against each of the folds and then finalise our model. After that, we test it against the test set.
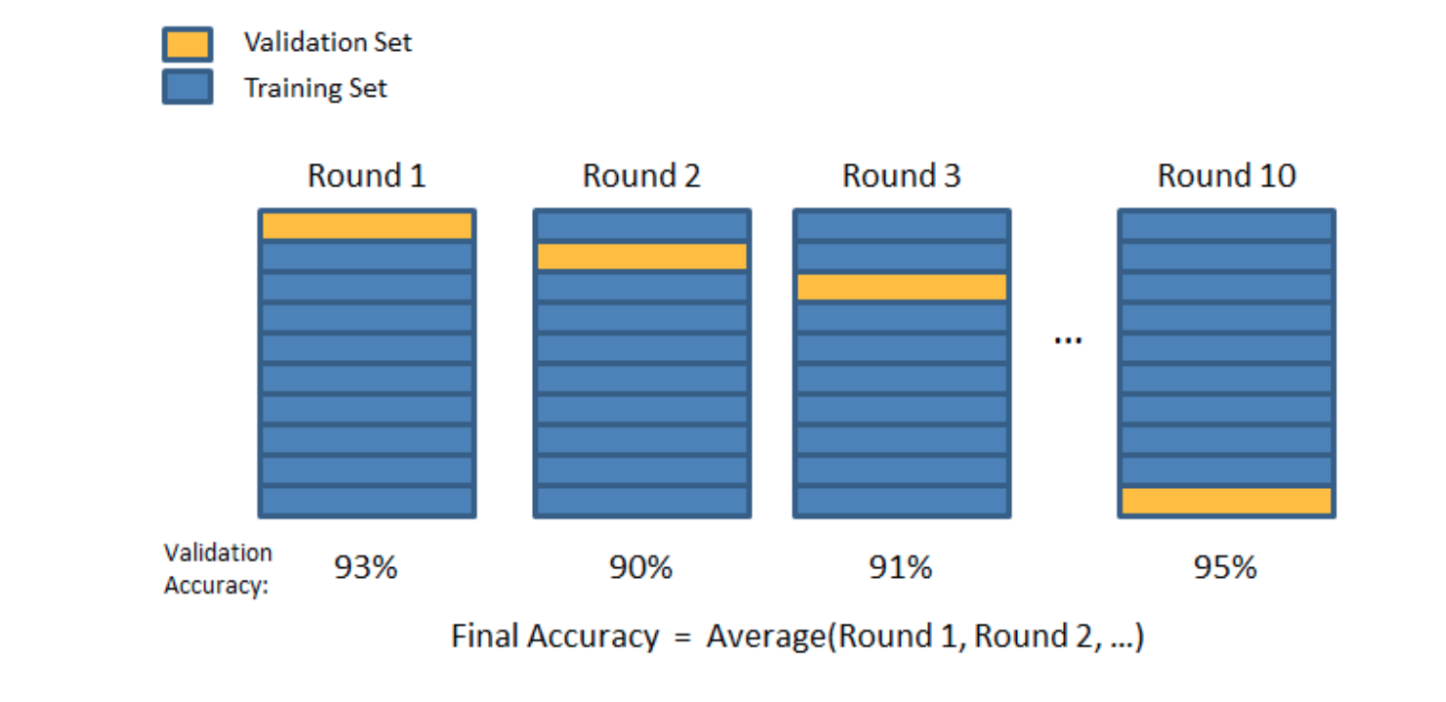
Here we use XGBoost model as example:
clf = XGBClassifier(min_child_weight = 10)
auc = []
kf = KFold(n_splits=5, random_state=None, shuffle=False)
# Define the split - into 5 folds
for train_index, test_index in kf.split(X):
X_train, X_test = X.iloc[train_index], X.iloc[test_index]
y_train, y_test = y.iloc[train_index], y.iloc[test_index]
y_pred =clf.fit(X_train, y_train).predict_proba(X_test)[:,1]
auc.append( metrics.roc_auc_score(y_test, y_pred))
print ("auc:",auc)
auc: [0.8605985154671234, 0.85948272342704934, 0.86374575922487207, 0.86286306523399336, 0.86806203745107979]
Cross_val_score
The following example demonstrates how to estimate the roc_auc (scoring=’roc_auc’) on the given dataset by splitting the data, fitting the XGBoost modle and computing the score 5 times (with different splits each time, cv=5):
clf = XGBClassifier()
scores = cross_val_score(clf, XScaled, yScaled, cv=5, scoring='roc_auc')
print("roc_auc: %0.4f (+/- %0.4f)" % (scores.mean(), scores.std() * 2))
roc_auc: 0.8627 (+/- 0.0068)
scoring can choose from a whole list of diffrent values:
http://scikit-learn.org/stable/modules/model_evaluation.html
Classification:
‘accuracy’ ‘average_precision’ ‘f1’, ‘f1_micro’ ‘f1_macro’ ‘f1_weighted’ ‘f1_samples’ ‘neg_log_loss’ ‘precision’ ‘recall’ ‘roc_auc’
Clustering:
‘adjusted_rand_score’
Regression:
‘neg_mean_absolute_error’ ‘neg_mean_squared_error’ ‘neg_median_absolute_error’ ‘r2’